How We Built a Serverless RFID Tracking API for 2,500 Antennas at $260/Month
The Problem
A global RFID deployment of 2,500 antennas across 350+ facilities in 50+ countries produces a constant stream of read events — every tagged item that passes under a reader generates a record. Those events land in an upstream EPCIS event store. The events sit there immutable, append-only, and high-volume. They're also not directly useful: each raw read carries only tag_id, reader_id, location_string, and timestamp. Downstream applications need a clean, deduplicated, enriched, query-fast view they can hit with a simple REST call — one that turns "tag X at reader Y" into "asset Z, originating from facility A in country B, headed to facility C in country D, currently seen at facility E."
We needed an API platform between the event store and the consumers. Three constraints made this harder than it looks:
- The upstream sender retries failed POSTs for ~10 minutes, then marks the event as permanently failed. Anything below ~99.9% uptime creates manual operational debt for someone else.
- The platform had to be sized for 10x current peak without a re-architect.
- All processing had to stay inside the EU (GDPR).
We built it fully serverless on AWS — no fixed-capacity servers anywhere on the data path, every tier scaling independently with load. The same architecture that handles today's 100k events/day handles 1M events/day with no code or template changes. This is how it works, and why it costs ~$260/month at typical load.
The Architecture
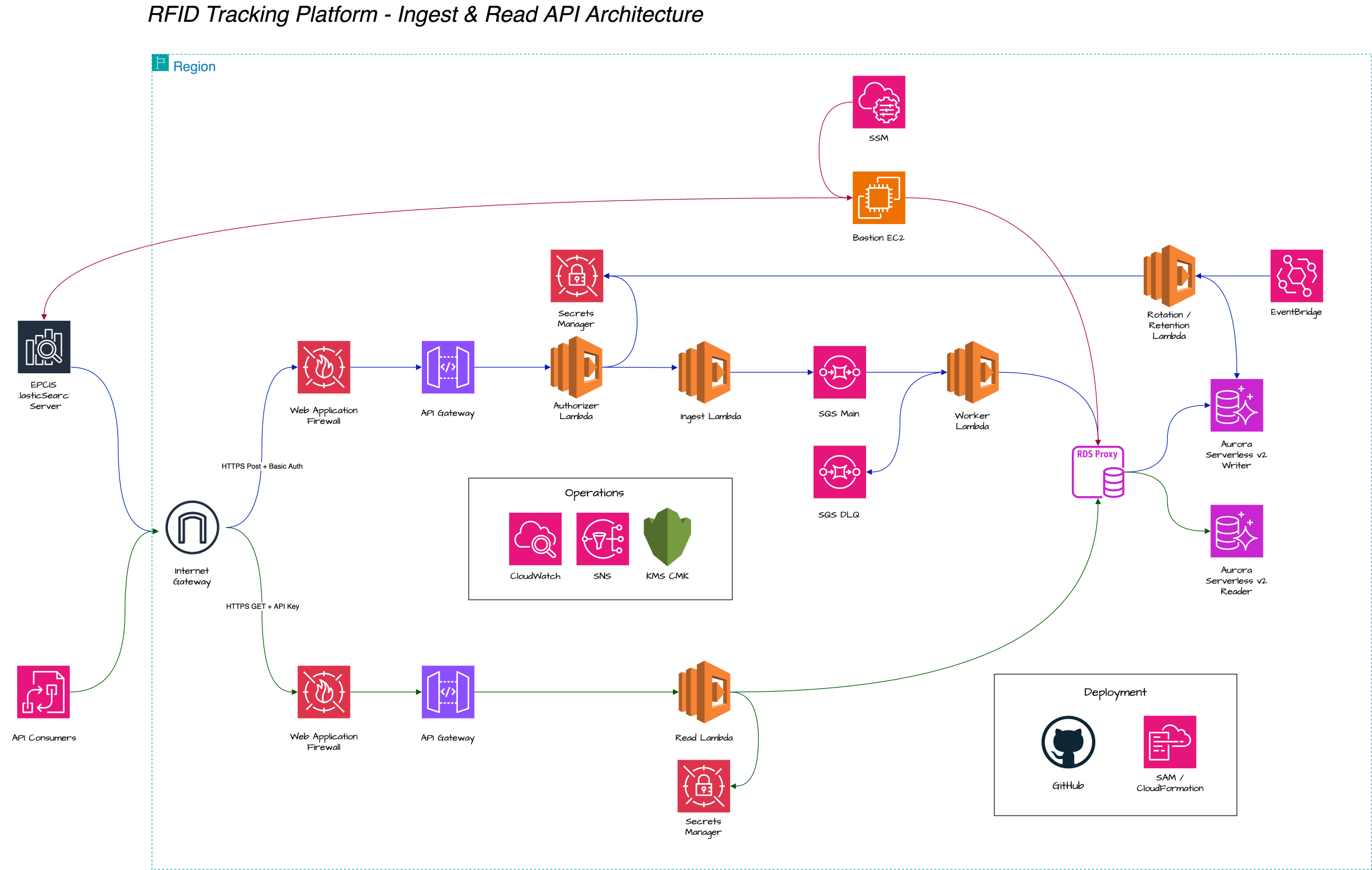
Everything runs in a single AWS region (Frankfurt, eu-central-1) across three availability zones. Two parallel HTTPS flows share the infrastructure: an ingest path for partners writing data in, and a read path for consumers querying it out.
Ingest path (async, tens of milliseconds to 202 Accepted)
- AWS WAF with a rate-based rule (200,000 requests / 5 min per source IP) and AWS Managed Rules. Throttled requests get a custom 429 response — important detail we'll come back to.
- API Gateway (REST) with a Lambda authorizer that validates HTTP Basic Auth against a bcrypt hash in Secrets Manager. The authorizer caches its IAM policy for 5 minutes, so credential checks don't run on every event.
- Ingest Lambda (outside VPC for fast cold starts) validates the payload shape — single event or batch — and pushes it onto SQS. Returns 202.
- SQS Standard queue buffers everything between the public endpoint and the database. Database hiccups never become ingest 5xx.
- Worker Lambda (in VPC, reserved concurrency) drains the queue in batches, bulk-inserts via RDS Proxy into Aurora's central reads table. PostgreSQL
AFTER INSERTtriggers then run three things atomically in the same transaction: dedup, fan-out to per-domain tables, and enrichment by joining the row against reference data (asset bindings, facility metadata, country codes, operator names). - Dead-Letter Queue with a CloudWatch alarm at depth ≥ 1.
Read path (synchronous)
API Gateway with API Key + Usage Plan rate limiting → Read Lambda (in VPC) → RDS Proxy → Aurora reader endpoint. Splitting writes (Worker → writer) and reads (Read Lambda → reader) means a heavy report query can't slow ingestion down.
Database layer (this is where the work happens)
Aurora Serverless v2 (PostgreSQL 16), Multi-AZ, 1–16 ACU per instance, monthly-partitioned reads tables with a scheduled retention Lambda that drops partitions older than 24 months. Encrypted at rest, 28-day point-in-time recovery, deletion protection at both cluster and instance level. Two database roles (ingest, reader) with automatic 30-day rotation via Secrets Manager.
The database isn't just storage — it's the transformation engine. Four classes of reference data sit alongside the reads tables: asset bindings (tag → asset), facility metadata (facility code → name, country, operator, function), location lookups (reader → facility), and code lists (ISO country codes, type codes, status codes). The AFTER INSERT triggers join the incoming row against all four. A SELECT against the enriched table returns 15–20 columns of pre-joined business context, not the 4 columns of the raw event. Consumers don't need to know reference data exists.
Ops
A bastion EC2 reached via SSM Session Manager (no SSH keys, no public ports) for break-glass access. EventBridge schedules retention and rotation Lambdas. CloudWatch dashboards with threshold annotations on every chart. SNS-backed alarms wired to email.
The entire stack is AWS SAM templates committed to GitHub. Three independent stacks (infra, ingest, read) each deploy to -dev and -prod.
The Cost
At typical load (~100k events/day, ~28 events/sec), monthly spend breaks down roughly:
- Aurora Serverless v2 Multi-AZ (idle to typical): ~$200–$300
- Application stack (Lambda, API Gateway, SQS, WAF, VPC endpoints, Secrets Manager, alarms): ~$50
- Storage: ~$5
Total: ~$260–$360/month.
Dev environment adds about $5/month because Lambda, API Gateway, and SQS are pay-per-use and the dev database shares the same Aurora cluster.
Key Engineering Decisions
Single region, not multi-region. We considered active-passive across two regions. We chose single-region with Multi-AZ instead. Single-region eliminates a class of replication-lag bugs, halves the operational surface, satisfies EU data residency cleanly, and recovers from any AZ failure in under a minute. The compute savings funded a more generous Aurora ACU ceiling.
Async ingest with SQS in the middle. The ingest Lambda's only job is validate and enqueue. Database problems, partition rebuilds, slow worker batches — none of it can ever cause an ingest 5xx. The upstream's 10-minute retry budget is never put at risk by anything happening on our side of the queue.
429, not 403, for WAF throttle. The upstream sender treats 429 as transient and retries automatically. It treats 403 as permanent and requires manual reset. The default WAF block response is 403. Changing it to 429 was three lines of YAML and a permanent reduction in manual ops work.
Dedup, fan-out, and enrichment in the database, not application code. All three transformations run as a PostgreSQL AFTER INSERT trigger chain in the same transaction as the insert. Dedup (per tag + read point, keep first + latest), fan-out to per-domain tables, and enrichment joins against reference data — atomic per record. There is no race condition path, no half-state where one table has the row and another doesn't, no enriched row missing its joins. The equivalent in application code would be three classes, an ORM, a transaction wrapper, retry semantics for each lookup, and a much larger surface area for bugs.
RDS Proxy is non-negotiable for Lambda + Aurora. Without it, every Lambda cold start opens a fresh database connection. Under burst, Aurora's max connection limit gets hit in seconds. RDS Proxy multiplexes onto a small pool with no perceptible latency cost.
Fully serverless top to bottom. API Gateway scales on request count. Lambda scales on concurrency. SQS scales on queue depth. Aurora Serverless v2 scales on ACU. No tier has a fixed-capacity instance that has to be sized manually, and no tier blocks the others when it has to scale. Capacity planning becomes a one-line SAM parameter change — raise Aurora's max ACU, raise Lambda's reserved concurrency, done. The platform absorbs a 10x growth in traffic without an architectural conversation.
What We Learned
Small protocol details have huge operational consequences. The 429-vs-403 choice is barely a line in the WAF documentation but it's the difference between "auto-recovers from a traffic spike" and "wakes someone up to clear stuck events." Read the retry semantics of every upstream client before you pick a status code.
Triggers eliminated a class of bugs we didn't write. Doing dedup, fan-out, and enrichment in the database means there's no application logic to get wrong. No race conditions, no half-states between tables, no enriched row missing its joins because a lookup service was slow. The trigger functions are versioned SQL in migrations, alongside the schema they operate on, and easier to reason about than the equivalent in any application language. The database already has the reference data sitting next to the reads — pushing the joins down to where the data lives is faster than pulling it up to the application tier.
Aurora Serverless v2 has a real idle cost. Min 1 ACU per instance × 2 instances Multi-AZ × $0.14/ACU-hour × 730 hours = ~$204/month baseline before any actual load. That's the price of Multi-AZ failover under a minute and burst headroom on tap. Worth knowing before you size the ACU floor.
Test the Multi-AZ failover early. The promise is "under one minute." The reality depends on how aggressively RDS Proxy reconnects, what timeouts your Lambdas have configured, and whether your client retries. Force a failover during a quiet hour and watch what happens — far cheaper than learning during an incident.
Two databases on one cluster is the dev/prod sweet spot. Same Aurora cluster, different logical databases, different SAM stacks pointing at each. Dev costs near-zero because all the application-tier services are pay-per-use. The only shared resource is the Aurora compute, which would idle at the same baseline either way.
Results
- Architecture: fully serverless across every tier — no EC2 on the data path
- Throughput cap: 200,000 requests / 5 min per source IP (~666 req/s)
- Current sustained load: ~28 events/sec, ~100k events/day
- Headroom: 10x current peak with no architectural change
- p95 ingest latency: under 100ms
- Multi-AZ failover: under 1 minute on AZ event
- Idempotency: duplicate sends are silent no-ops at DB level
- Cost: ~$260–$360/month at typical load
- 24-hour stress test at 20x normal throughput: Aurora peaked at 4 ACU, single-digit concurrent Lambdas, zero alarm thresholds crossed
If you're building a high-throughput ingest API on AWS and want a second pair of eyes on it, or if you'd like us to design and ship one for your team — get in touch.